【JavaScript】 Punycodeの仕組みと実装
更新日:2024/02/27
日本語が混ざった文字列をドメインとして使用する場合、Punycodeという規格で変換され文字をドメインとして登録します。
今回僕は、Punycode変換ツールを作成するためにPunycodeについて調査してみました。
Punycodeの前提知識
まずは前提として知っておくべきPunycodeの知識を挙げておきます。
Punycodeとは
Punycodeは国際化ドメイン名を、数値とアルファベットおよび記号で表現したものです。
いわゆる2バイト文字が含まれているドメイン名を国際化ドメイン名と呼びますが、国際化ドメイン名のままではドメインの管理機関に登録することができません。
そこで独自のアルゴリズムで国際化ドメイン名を1バイトの数値とアルファベットおよび記号のみに変換する必要があります。
そのために標準化されたのが、Punycodeです。
Punycodeは、Bootstringという文字列のエンコード/デコード方式をドメイン名に適用したものです。
PunycodeはRFC3492で規定されています
■Punycode: A Bootstring encoding of Unicode for Internationalized Domain Names in Applications (IDNA)
Punycodeは、例えば大文字と小文字のアルファベットなど表現の異なる同一のドメイン名の正規化については関与していません。
正規化についてはNameprep: A Stringprep Profile for Internationalized Domain Namesで既定されています。
Punycodeの文字コード
Punycodeで用いられる文字コードはUnicodeで統一されています。
そのためWebページによくある、文字コードが異なると文字化けをおこすようなことはありません。
必ず同じ文字に変換されます。
Unicodeは日本語だけでなく、他の言語の文字を一つのコードに詰め込むことを目的としたものです。
そのためPunycodeは、世界中の言語に対応しています。
■表記例
[日本語] おはよう : xn--p8jh5i5d
[ネパール語] शुभ-प्रभात : xn----pvdrkcr2b7dva7j
[マケドニア語] добро утро : xn--90af4abakbpi
Punycodeの構成
元となるドメイン名の1バイトおよび2バイト文字の構成によって、生成されるPunycodeの構成が決まります。
■1バイト文字のみ
Punycodeで表現する必要性がないので、そのままの文字が使用されます。
abcde → abcde
■2バイト文字のみ
"xn--" の後、数値またはアルファベットが続きます。
あいうえお → xn--l8jegik
■1バイトと2バイト文字が混在
"xn--" の後、順番に抜き出された1バイト文字が続き、"-" の後、数値またはアルファベットが続きます。
あaいbうcえdお → xn--abcd-u53cnaprt
元となるドメイン名に "-" が含まれる場合、最後の "-" が区切りとして認識されます。
---あaい-bうc--えdお--- → xn-----a-bc--d----rz3l5a8a0bzb
Punycodeの仕組み
仕組みの概要
まずは変換後の構成について確認しています。
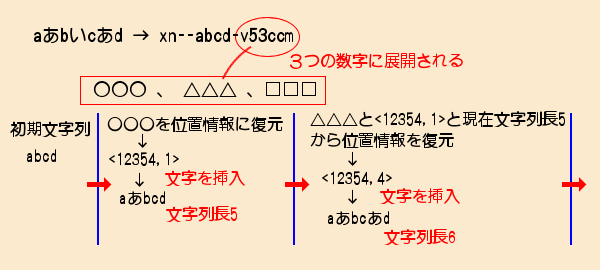
元となる文字列に1バイトと2バイト文字が混在する場合、変換後のPunycodeの形式を次のように定義します。
xn--①-②
この時①は、元となる文字列から1バイト文字を抜き出したものです。
そして②は、残った2バイト文字を①への挿入するために必要な情報を暗号化したものです。

挿入位置を求める
次の文字列で、挿入位置を導き出してみます。
例として用いる文字列: "aあbいcあd"
抜き出した文字列: "abcd"
"あ"の文字コード : 12354
"い"の文字コード : 12356
この例では "abcd"に、残った3つの文字 "あ""い""あ"を挿入していきます。
ですが並び順で挿入していくわけではありません。
文字コードが小さいもの順で、同じコードなら最初に現れる文字から挿入していきます。
最初に該当するのは、一番目の"あ"です。
"あ"は"a"と"b"の間に挿入されます。
このときの情報を、<コード,挿入位置>であらわします。
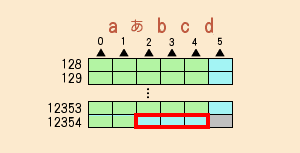
挿入位置の番号は文字列の前が0で、文字列の最後が文字列の長さです。
次のようなイメージです。
| 現在の文字列 | a | b | c | d | |||||
| 挿入可能位置 | ↑ | ↑ | ↑ | ↑ | ↑ | ||||
| 挿入インデックス | 0 | 1 | 2 | 3 | 4 |
次のようになります→<12354,1>
次の文字は、2番目の"あ"です。
前回の文字を挿入した後の文字 "aあbcd"に、挿入します。
同様に3番目も処理します。
全ての結果は、次の表のようになります。
| 挿入される文字 | "abcd" | → | "aあbcd" | → | "aあbcあd" |
| 文字数 | 4 | 5 | 6 | ||
| 挿入する文字 | "あ" | "あ" | "い" | ||
| 挿入情報 <コード,位置> | <12354,1> | <12354,4> | <12356,3> |
後は挿入情報を文字列化すればいいのですが、データ量を減らすために差分を求めていきます。
エンコードの考え方
RFC3492では、位置情報を< n , i >のカウンターと見立てて、i に1を加算して左端に到達したら n に1 を加算します。
nがコード値と一致してiが挿入位置に到達した時点での、i に1を加算した回数が求める値になります。
これを最初の位置情報について適用すると、次のようなイメージになります。
コード値127以前は1バイト文字の領域なので、除外されます。
一番目
二番目は次のようになります。
二番目
三番目は次のようになります。
三番目
図から一番目の緑枠の数を、次のような計算で求めます。
( 12354 - 128 ) × ( 4 + 1 )+ 1 → 61131
これが、一番目の位置情報を数値化したものになります。
61131を文字列に変換して出力します。
二番目は、一番目の差分で考えます。
二番目の図に一番目の図を重ねてみます。
図から差分が3であることがわかります。
コードが12353以前も増えていますが、この部分は無視です。
このとき、差分は必ず1以上になります。
そのため、位置情報として1を引いておくことができます。
つまり 3 - 1 で 2が、2番目の位置情報になります。
2 を文字列に変換して出力します。
三番目も同様に考えます。

図から差分が13であることがわかります。
位置情報は、13 - 1 で 12 です。
12 を文字列に変換して出力します。
これはあくまで考え方です。
実際のアルゴリズムは桁溢れをおこさないような方法で計算がおこなわれています。
デコードの考え方
デコードは入力された文字列を数値に変換します。
直前に処理したコード値と挿入位置を基準として、変換した数値を加算していきます。
次の式で<コード値,挿入位置>を計算します。
コード値: ( 差分 + 前回の挿入位置 + 1 ) ÷ (現在の文字数 + 1) + 前回のコード
挿入位置: ( 差分 + 前回の挿入位置 + 1 ) を (現在の文字数 + 1) で割った時の余り
ただし初回のみ、次の値を使用します。
前回のコード:128
前回の挿入位置:-1
今回のケースに当てはめてみます。
■初回
変換した数値:61131
現在の文字数: 4
前回の情報: <128,-1>
コード値: ( 61131 + -1 + 1 ) ÷ (4 + 1) + 128 → 12354
挿入位置: ( 61131 + -1 + 1 ) を (4 + 1) で割った時の余り→ 1
■2回目
変換した数値:2
現在の文字数: 5
前回の情報: <12354,1>
コード値: ( 2 + 1 + 1 ) ÷ (5 + 1) + 12354 → 0 + 12354 → 12354
挿入位置: ( 2 + 1 + 1 ) を (5 + 1) で割った時の余り → 4
■3回目
変換した数値:12
現在の文字数: 6
前回の情報: <12354,4>
コード値: ( 12 + 4 + 1 ) ÷ (6 + 1) + 12354 → 2 + 12354 → 12356
挿入位置: ( 12 + 4 + 1 ) を (6 + 1) で割った時の余り → 3
元の情報と一致しました。
数値の文字列化と区切りの判定機能
位置情報を数値化した値は36進数に変換され、下位桁から出力されます。
ただし16進数などのように"0"から始まるのではなく、"a"からスタートします。
0から25 : ""から"z"
26から35: "0"から"9"
最初の情報が出力されたら、続けて次の情報が出力されます。
ここで大きな問題に直面します。
例えば"ad04bfa"のような文字列があった場合、一番目はどこで区切ればいいのでしょうか?
Punycodeは区切りを判定する仕組みが組み込まれています。
各桁と閾値
各桁は各桁ごとに計算で閾値が求められます。
そして次の条件を満たすとき、最上位桁をみなされます。
最上位桁の条件:桁の値 < 閾値
つまり、最上位桁は閾値を超えるように、最上位桁以外は閾値を超えるように調節されるということです。
『そんなことは可能なのか?』と疑問が湧いてきますきますが、一般化可変長整数という考え方で実現できます。
一般化可変長整数は次の式で求めます。
桁の値: (数値 - 閾値) % (基数 - 閾値) + 閾値
次桁の数値: (数値 - 閾値) ÷ (基数 - 閾値)
次の記事で一般化可変長整数について、もう少し詳しく書いています。
■【JavaScript】 区切記号なし連続した数値文字列の生成と復元
Punycodeの閾値
一般化可変長整数そのものは汎用的なもので、基数や閾値の具体的な値については定義されていません。
そのため、Punycodeとして特有の値が決められています。
基数は36です。
閾値は次の計算で求めます。
桁nの閾値: 基数36 × n - bias
※nは0~
計算結果が定数tmin= 1 から 定数tmax= 26 の範囲から外れるときは、tminまたはtmaxに丸められます。
biasは、計算で求められる値です。
計算方法は後述します。
閾値の計算の結果は、ほとんどが1か26です。
biasの値が大きいほど、1となる桁数が増えます。
基数36 × nの結果が bias + 2 から bias + 25 の範囲のときのみ、計算結果が範囲内となります。
基数36 × nは桁上がり毎に36が加算されるので、範囲内となる回数は、0回か1回のみです。
biasの計算
biasの計算は次のようなコードでおこないます。
const DAMP = 700;
const BASE = 36;
const TMIN = 1;
const TMAX = 26;
const SKEW = 38;
const adapt = (delta, stringLength, firsttime ) => {
// 桁溢れ対策でdeltaを縮小
delta = Math.floor( firsttime ? delta / DAMP : delta / 2 );
// 前回よりも文字列が増えてるからdeltaを増やす
delta += Math.floor(delta / stringLength );
let k;
// 次のデルタに必要な桁の最小数を予想
for (k = 0; delta > (BASE - TMIN)*TMAX/2; k += BASE) {
delta = Math.floor(delta / (BASE - TMIN) );
}
// 最下位桁~最上位-3までが 閾値tmin
// 最上位桁が閾値tmaxになるように返す
return Math.floor(k + (BASE - TMIN + 1) * delta / (delta + SKEW));
};
deltaは、前回と前々回のコード値の差です。
例えば次の3つの位置情報があって、③の処理しているとします。
①<12354,1> ②<12354,4> ③<12356,3>
このときのdeltaは、②のコード値から①のコード値を減算した結果なので、0です。
stringLengthは現在の文字列長で、firsttimeは初回の挿入のときtrueになります。
RFC3492によると、biasの計算目的は次に来る文字を表現するのに最適な閾値を求めることです。
しかし次に来る文字は、同じコードかもしれませんし、日本語以外の文字で非常に離れたコードかもしれません。
これを予想することは不可能です。
そのため、最適な値を求めるのも不可能です。
あまり意味のない計算のような気がしますね。
しかしこの計算でbiasを変化させることで、閾値が1から26に切り替わるタイミングを変動できます。
これにより、解読を難しくできているので意味があるのかもしれません。
JavaScriptコード
RFC3492には、c言語でPunycode変換のコードが掲載されています。
掲載されているコードは、①エンコードとデコード、②コンソールからの入力を処理してエンコードとデコードに渡すラッパーの二つの機能に分かれています。
今回は①をJavaScriptに置き換えてみます。
c言語からJavaScriptへの置き換えでは、次の点に注意する必要があります。
- 整数の計算
元コードの各変数は符号なしの整数で定義されていて、演算は整数に丸められます。
しかしJavaScriptの数値は浮動小数点のみのため、結果が小数になる場合は切り捨てる必要があります。 - 文字列の取り扱い
c言語の文字コードは、環境によって変化します。
そのため、入力された文字がUnicodeでない場合、変換をおこなう必要があります。
元のコードでは、文字変換を行わずに、コンソールからu+XXXXという形式で直接Unicode値を指定しています。JavaScriptの内部文字コードはUnicodeに統一されています。
そのため、文字コード変換などの作業は不要です。JavaScriptの文字列と文字コードの関係について次のページを読んでみてください。
■【JavaScript】 文字列データの内部形式と関連メソッドについてまとめてみた
コードの全文を一度に掲載するとわかり難くなるので、共通部分、エンコード部分、デコード部分の3つに分割して掲載します。
共通部分
共通部分のコードです。
このコードを実行すると、2つのメソッドを持ったオブジェクトを返します。
const jsPunyCode = (()=>{
// Punycodeの開始文字列
const START_STRING = "xn--";
// 各種パラメーター
const BASE = 36, TMIN = 1, TMAX = 26, SKEW = 38, DAMP = 700,
INITIAL_BIAS = 72, INITIAL_N = 0x80,
DELIMITER_STRING = "-" , DELIMITER = DELIMITER_STRING.codePointAt(0);
// 変数の最大値
const MAXINT = Number.MAX_SAFE_INTEGER;
// 基本文字(1バイト文字)かどうかの判定
const isBasicChar = c => c < 0x80;
// 閾値の計算
const calculationT = (k,bias) => k <= bias ? TMIN :
(k - bias >= TMAX ? TMAX : k - bias);
// encode_digit:数値→文字変換 decode_digit:文字→数値変換
// 0~25:a~z 26~:0~
const [encode_digit,decode_digit] = (()=>{
const [NUM0_CODE,NUM25_CODE,NUM26_CODE,NUM35_CODE] =
["a","z","0","9"].map( e=>e.codePointAt(0) );
const CODE_ZERO_OFFSET = NUM26_CODE - 26;
const encode_digit = d =>
d < 26 ? d + NUM0_CODE : d + CODE_ZERO_OFFSET;
const decode_digit = cp =>
cp <= NUM35_CODE ? cp - NUM26_CODE + 26: cp - NUM0_CODE;
return [encode_digit,decode_digit];
})();
// biasの計算
const adapt = (()=>{
const PARAM1 = BASE - TMIN;
const PARAM2 = PARAM1*TMAX/2;
const PARAM3 = PARAM1 + 1;
return (delta, stringLength, firsttime ) => {
delta = Math.floor( firsttime ? delta / DAMP : delta / 2 );
delta += Math.floor(delta / stringLength );
let k;
for (k = 0; delta > PARAM2; k += BASE) {
delta = Math.floor(delta / PARAM1 );
}
return Math.floor(k + PARAM3 * delta / (delta + SKEW));
};
})();
/**
* 文字列からPunycodeへのエンコード
*/
const encode = inputString =>{ /* 内容はこちら */ };
/**
* Punycodeから文字列へのデコード
*/
const decode = inputString =>{ /* 内容はこちら */ };
return {
encode : encode,
decode : decode
}
})();
エンコード部分
エンコード部分のコードです。
共通部分のencodeの内容です。
元コードは出力文字を大文字または小文字に強制するフラグを引数として受け付けますが、ここでは実装していません。
統一ぜずに、そのまま出力しています。
入力文字のチェックもしていません。
コード値0x80未満は基本文字としてそのまま使用されます。
エラーが発生したら、nullを返します。
/**
* 文字列からPunycodeへのエンコード
*/
const encode = inputString =>{
// 入力文字列をコードポイント単位の配列に変換
const inputArray =
[...inputString].map( c => c.codePointAt(0) );
const input_length = inputArray.length;
// 基本文字を選別
const output = inputArray.filter(isBasicChar);
// 全ての文字が基本文字なら終了
if( input_length === output.length ) return inputString;
let codeNumber = INITIAL_N; // 出力対象文字コード
let delta = 0; // 挿入位置を指示する値
let bias = INITIAL_BIAS;
let outputLength = output.length; // 現在の変換済み文字数
let firstOutputFlg = true; // 初回出力フラグ
if( outputLength > 0 ) output.push( DELIMITER );
while (outputLength < input_length) {
// 前回のcodeNumber+1より大きいものから最小のものを検索
// (codeNumberはwhileの最後で+1されている)
const m = inputArray.reduce(
(a,b)=> b >= codeNumber && b < a ? b : a
,MAXINT);
// 桁溢れチェック
if (m - codeNumber > (MAXINT - delta) / (outputLength + 1))
return null;
// 前回出力対象コードの差分を元に挿入位置を指示する値を算出
delta += (m - codeNumber) * (outputLength + 1);
// 前回出力対象コードを現在の出力対象コードで更新
codeNumber = m;
for (let j = 0; j < input_length; ++j) {
const c = inputArray[j];
if ( c < codeNumber ) // 基本文字または処理済み文字
++delta; // <n,i>のiを加算
else if ( c === codeNumber ) { // 今回の出力対象コード
let q = delta, k = BASE;
let t = calculationT(k , bias);
while( q >= t ){
output.push( encode_digit(t + (q - t) % (BASE - t)) );
q = Math.floor((q - t) / (BASE - t) );
k += BASE;
t = calculationT(k , bias);
}
output.push( encode_digit(q) );
bias = adapt(delta, outputLength + 1, firstOutputFlg);
delta = 0;
firstOutputFlg = false;
++outputLength;
}
}
++delta;
++codeNumber;
}
return `${START_STRING}${ output.map( c=>String.fromCodePoint(c) ).join("") }`;
};
Punycodeの仕組みの解説では、全ての位置情報を求めてから差分計算しているような印象を受けるかもしれませんが、ここでは一文字ごとに位置情報の算出と差分計算しています。
コードの最初に1バイト文字を配列outputに抽出しています。
しかし配列outputは出力用の文字バッファで、以後の処理に関与しません。
アルゴリズムでは、1バイト文字列に2バイト文字列を挿入した結果生成された文字列に対して、残った文字列を挿入する位置を算出しています。これは、inputStringをコードポイントの配列化したinputArrayを走査することで決定されます。
■例
次のような文字列を文字コードに置き換えます。
aいbcあde → 0x61 0x3044 0x62 0x63 0x3042 0x64 0x62
0x3042("あ")を処理するときの処理済み文字列は、0x3042以下を抽出することで得ることができます。
つまり、次のようになります。
0x61 0x62 0x63 0x64 0x62 → abcde
0x3042の挿入位置の算出は、前方から順番に文字を確認して、0x3042以下ならカウントアップします。
0x3042が出現したら、そのときのカウント数が挿入位置です。
デコード
デコード部分のコードです。
共通部分のdecodeの内容です。
元コードは"xn--"が無い状態の文字列を受け付けます。
しかしこのコードでは、"xn--"が必須です。
encodeと同様に出力文字を大文字または小文字に強制するフラグを引数として受け付けますが、ここでは実装していません。
統一ぜずに、そのまま出力しています。
入力文字のチェックもしていません。
コード値0x80未満は基本文字としてそのまま使用されます。
エラーが発生したら、nullを返します。
/**
* Punycodeから文字列へのデコード
*/
const decode = inputString =>{
// 基本コードと拡張文字列の分割
const [output,inputArray] = (( )=>{
const s1 = inputString.toLowerCase().substring(START_STRING.length);
const delimiterPos = s1.lastIndexOf( DELIMITER_STRING );
return (delimiterPos === 0 ? ["",s1] :
[s1.substring(0,delimiterPos),s1.substring(delimiterPos+1)])
.map( string => [...string].map( c=>c.codePointAt(0) ) )
})();
const input_length = inputArray.length;
let codeNumber = INITIAL_N;
let index = 0;
let bias = INITIAL_BIAS;
let inPos = 0;
let firstOutputFlg = true; // 初回出力フラグ
do{
let beforeIndex = index;
let w = 1; // 重み
let k = BASE; // 閾値判定用の変数
let digit,t;
do{
if (inPos >= input_length) return null;
// 文字を数値に変換
digit = decode_digit(inputArray[inPos++]);
index += digit * w;
// 閾値を計算
t = calculationT( k , bias );
// 最上位桁かどうかチェック
if (digit < t) break;
// 桁溢れチェック
if (w > MAXINT / (BASE - t)) return null;
w *= (BASE - t);
k += BASE;
}while( digit >= t );
const oLength = output.length + 1;
bias = adapt(index - beforeIndex, oLength, firstOutputFlg);
firstOutputFlg = false;
// 桁溢れチェック
if (index / oLength > MAXINT - codeNumber) return null;
codeNumber += Math.floor(index / oLength);
index %= oLength;
// 配列に文字を挿入
output.splice( index , 0 , codeNumber )
index++;
}while( inPos < input_length );
return output.map( c=>String.fromCodePoint(c) ).join("");
};
テスト
作成したコードをテストしてみます。
const test = s =>{
const a1 = jsPunyCode.encode(s);
if( s === a1 ) console.log( s , "対象ではありません" );
else console.log( `${s}\n → ${a1}\n → ${ jsPunyCode.decode( a1 ) }`);
}
test("JavaScript");
test("Punycodeは国際化ドメイン名を、数値とアルファベットおよび記号で表現したものです。");
test("Hello!こんにちは-bye!さよなら");
結果は次のようになります。
JavaScript 対象ではありません Punycodeは国際化ドメイン名を、数値とアルファベットおよび記号で表現したものです。 → xn--Punycode-mm3gka50fye0a7fxfcm6im7f7ple2jlnya2cx7dieva97aje2klm9ij590hmfwanohqxas20gxd2kfzofggzhxfpa903k → punycodeは国際化ドメイン名を、数値とアルファベットおよび記号で表現したものです。 Hello!こんにちは-bye!さよなら → xn--Hello!-bye! -u63k7a5nzfj7e5zva2r → hello!こんにちは-bye!さよなら
Punycode変換ツールへの適用
Punycodeの変換ができるようになったら次にやるのは変換ツールの作成ですね!
しかし断念しました。
そもそもPunycodeは国際化ドメイン名(IDNA)での使用を目的としたものです。
同じ文字でもコンピューター内部では異なるコードを使用しているケースもあります。
さらにドメイン名は大文字と小文字を同じものとみなします。
そして、全角の英数字やカタカナは半角として扱います。
これ以外にも様々な決まりごとがあります。
これらを正規化することを目的とした規定がStringprep(RFC3454)で、国際化ドメイン名への具体的な適用方法を定めたのがNameprep(RFC3491)です。
たぶん・・・
つまり、Punycode変換を行う前に、これらの規格に従って入力された文字列を正規化する必要があります。
必死の思いでPunycodeを理解したのに、今度は別の規格なんて・・・
心が折れました。
ネット上ではPunycode変換を行うツールが多数存在しています。
しかし正規化をおこなっているかどうかは、ツール次第です。
正規化を行っていない場合、ドメイン名として有効とは限りません。
つまり信用できないツールと言われてしまいます。
とても嫌ですね・・・
更新日:2024/02/27
関連記事
スポンサーリンク
記事の内容について

こんにちはけーちゃんです。
説明するのって難しいですね。
「なんか言ってることおかしくない?」
たぶん、こんなご意見あると思います。
裏付けを取りながら記事を作成していますが、僕の勘違いだったり、そもそも情報源の内容が間違えていたりで、正確でないことが多いと思います。
そんなときは、ご意見もらえたら嬉しいです。
掲載コードについては事前に動作確認をしていますが、貼り付け後に体裁を整えるなどをした結果動作しないものになっていることがあります。
生暖かい視線でスルーするか、ご指摘ください。
ご意見、ご指摘はこちら。
https://note.affi-sapo-sv.com/info.php
このサイトは、リンクフリーです。大歓迎です。


