エンディアンとは何か調べてみた
更新日:2021/06/18
コンピューターに関する用語でエンディアンというものがあります。
プログラミングではあまり目にすることがありませんが、概念として知っておくと今後目にしたときに役立ちます。
そこで今回は、エンディアンについてお伝えします。

CPUとエンディアン
エンディアンについて解説をするにあたって、CPUとメモリアクセスの話が欠かせません。
そこでCPUとメモリアクセスについて、簡単に解説します。
コンピューターのCPUは、レジスタという高速な記憶装置を複数持っています。
レジスタの数はCPUによって異なり一般的にな数個から数十個です。
コンピューターは、このレジスタに値をセットしてから計算をおこないます。
そして、メモリにデータを記憶するときにも、レジスタが使用されます。
一般的にはメモリは8ビット(1バイト)毎にアドレスが割り振られています。
そのためレジスタから1バイトをメモリに保存する場合、そのまま指定されたアドレスにセットされます。

複数バイトのデータ記憶もレジスタが使用されます。
例えば、16進数で 01020304、10進数で16909060をメモリに記憶するとき、次のようなイメージになります。
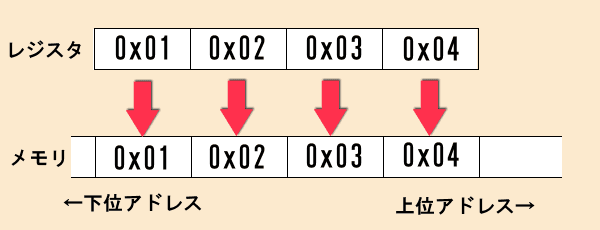
上の図を見るとデータを順番に格納しているので、素直に納得できると思います。
しかしCPUは一種類だけでなく、様々なメーカーが用途に合わせて作成しているので、無数に存在します。
その中には、下図のようにバイトの並びが逆転するものもあります。
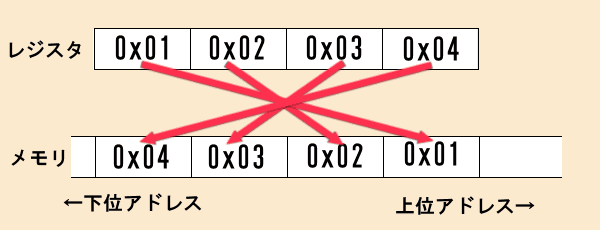
このように書くと、最初の例が主流のように受け取ることができますがどちらも利点があり、両方の方式が混在しています。
ビッグエンディアンとリトルエンディアン
エンディアンとは、前項で解説したようなバイトの並び順を表す用語で、大きく分けてビッグエンディアンとリトルエンディアンの二つに分類されます。
ビッグエンディアン
ビッグエンディアンは、プログラム上での数値表現と同じ順番でバイトを扱います。
例えば16進数で 01 02 03 04 という値をビッグエンディアンでメモリに格納すると、次のようになります。
| ←下位アドレス | アドレス増加分 | 上位アドレス→ | |||
| +1 | +2 | +3 | +4 | ||
| 01 | 02 | 03 | 04 | ||
なお、2バイト(16ビット)を1アドレスとして扱うケースもあります。
その場合は、次のようになります。
| ←下位アドレス | アドレス増加分 | 上位アドレス→ | |
| +1 | +2 | ||
| 01 02 | 03 04 | ||
リトルエンディアン
リトルエンディアンは、ビッグエンディアンとは逆に、下位バイトからメモリに格納していきます。
例えば16進数で 01 02 03 04 という値をビッグエンディアンでメモリに格納すると、次のようになります。
| ←下位アドレス | アドレス増加分 | 上位アドレス→ | |||
| +1 | +2 | +3 | +4 | ||
| 04 | 03 | 02 | 01 | ||
2バイト(16ビット)を1アドレスとして扱う場合は、次のようになります。
| ←下位アドレス | アドレス増加分 | 上位アドレス→ | |
| +1 | +2 | ||
| 03 04 | 01 02 | ||
その他のエンディアン
リトルエンディアンとビッグエンディアンに分類されないエンディアンは、ミドルエンディアンと呼ばれることがあります。
エンディアンはメモリ配置だけではない
ここまでは、メモリ記憶を例にしてエンディアンを解説してきましたが、実際にはディスクなどへの記録、ネットワーク等を利用したデータ送信時など、もっと広い範囲で使用される用語です。
エンディアンとバイナリファイル
僕がプログラマーとして就職したころは、コンピューターが非常に高価でした。
そのため、特定のコンピューター(パソコン)で動作させることが前提の上で、ソフト開発をおこなっていました。
多くの場合、ソフトの動作に必要な設定データはメモリの内容をそのままファイル保存していました。
そして、起動時にファイルからそのままメモリに読み込んで、保存時と同じ変数構造を当てはめていました。
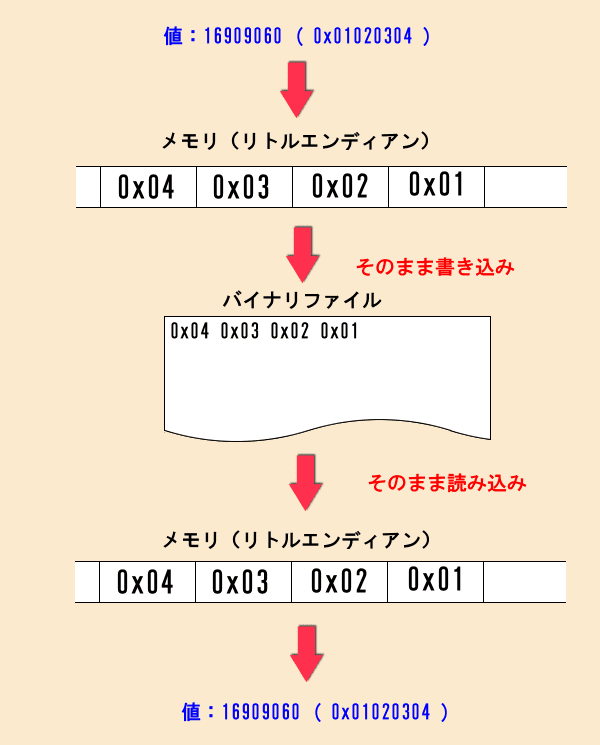
このロジックはエンディアンを意識する必要がなく処理が単純なので高速です。
ただし最初に書いていますが、これは、エンディアンが同じCPU間でデータを読み書きすることが前提です。
現在のソフトウェアは、エンディアンが異なるCPUで動作することが求められています。
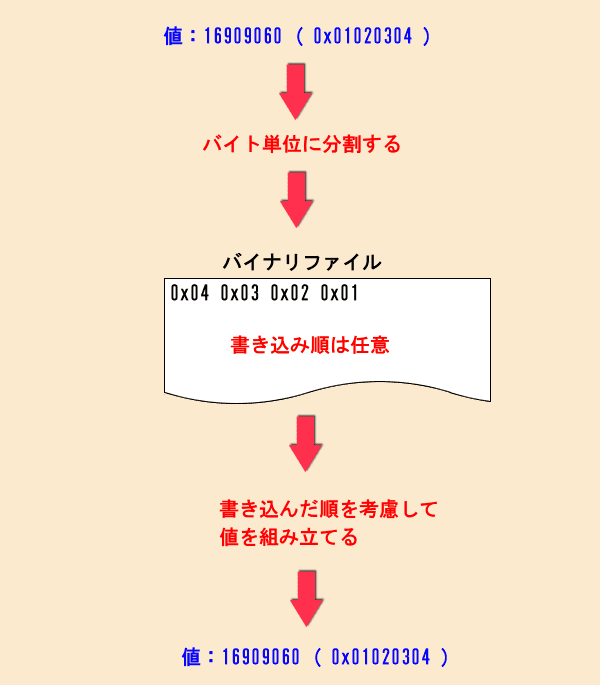
もしエンディアンが異なるCPU間で、昔僕がやっていたようなデータのやり取りをしたら、データの値が変わってしまいます。

そのため、自分でエンディアンを意識してファイル出力し、読み込み時は、エンディアンを意識して数値を構築してから変数にセットする必要があります。
エンディアンとテキストファイル
次の記事でも少し触れていますが、エンディアンはテキストファイルでも重要な概念です。
日本語の漢字やひらがな・カタカナは2バイト文字と呼ばれることがあります。
一つの文字(データ)が複数バイトで構成されるので、どのような順番でバイトを取り扱うのかというエンディアン問題を考える必要があります。
しかし実際には、プログラム上で考慮する必要はありません。
テキストファイルの出力または読み込みは、UTF-8やShift-JISなどのエンコード方法を指定します。
このエンコードに、エンディアンをどうするのかという定義が含まれているので、内部的に処理してくれるのです。
更新日:2021/06/18
関連記事
スポンサーリンク
記事の内容について

こんにちはけーちゃんです。
説明するのって難しいですね。
「なんか言ってることおかしくない?」
たぶん、こんなご意見あると思います。
裏付けを取りながら記事を作成していますが、僕の勘違いだったり、そもそも情報源の内容が間違えていたりで、正確でないことが多いと思います。
そんなときは、ご意見もらえたら嬉しいです。
掲載コードについては事前に動作確認をしていますが、貼り付け後に体裁を整えるなどをした結果動作しないものになっていることがあります。
生暖かい視線でスルーするか、ご指摘ください。
ご意見、ご指摘はこちら。
https://note.affi-sapo-sv.com/info.php
このサイトは、リンクフリーです。大歓迎です。


